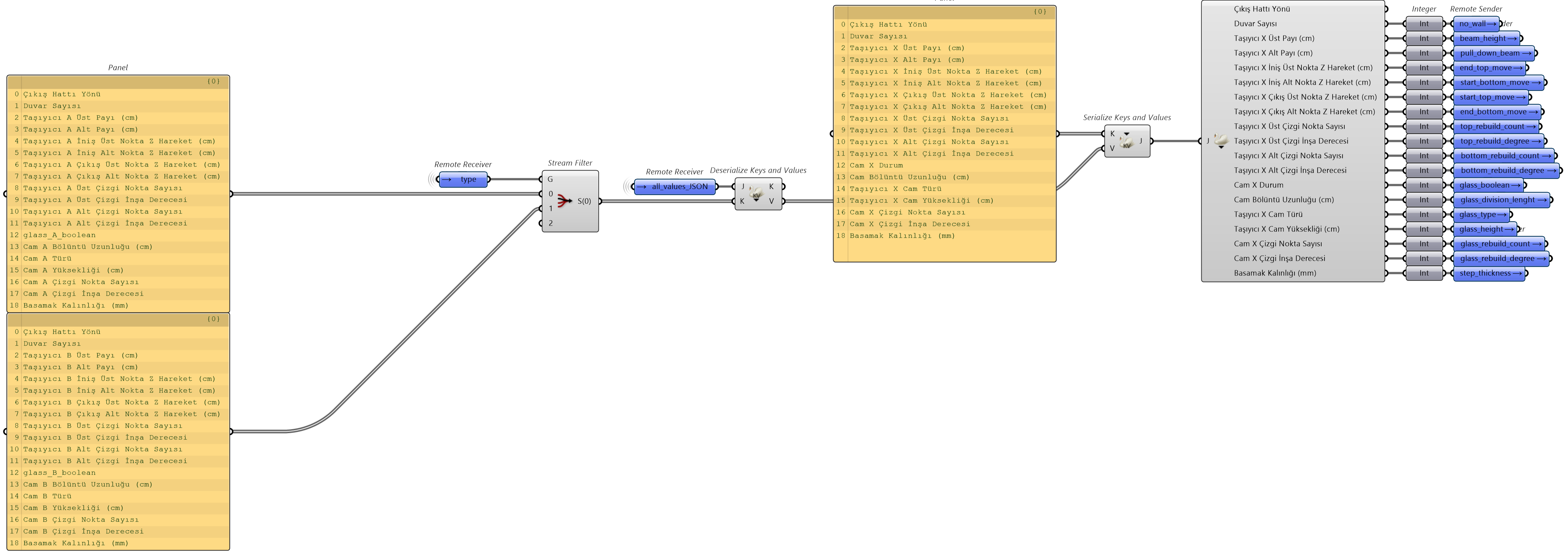
There are more than 100 different inputs that might be used or not and connecting them one by one to Hops components would be impractical. Therefore, a custom data management system was developed to handle this complexity efficiently. Data from each expander is collected and serialized with the names all values are merged and then data is seperated for each Hops component and deserialized in hops, resulting only needed data is sent to each Hops component.
The central data collection system has also introduced a challenge: since as one JSON value has changed the system run again and unrelated input changes would trigger unnecessary recomputations across unrelated Hops components.
To address this, a custom locking mechanism was implemented. Before propagating input values to each Hops component, the system checks whether the relevant data has actually changed. If no changes are detected, the input is held, effectively bypassing redundant updates and preventing the recomputation of components unrelated to the modified parameter.
This approach significantly improves performance by reducing unnecessary data flow and recomputation within Grasshopper and Hops workflows.
Many symmetrical components share the same Hops clusters but accept different inputs such as varying beam widths despite using identical definitions.
Since deserialization requires constant keys, a gate system is used to extract values by type, reconstruct a new JSON structure with fixed keys, and then deserialize it. This ensures that each Hops component maintains a consistent and reliable data structure, even when inputs names vary.
Each inner cluster typically requires around five or less inputs. This method not only ensures structural consistency in deeper parts of the algorithm but also keeps the input management tidy and well-organized.